Using container images with AWS Lambda
The serverless landscape just got massively expanded
Introduction
Container Image Support has just been announced for AWS Lambda and it’s a pretty big deal — I’m very excited because it’s something I’ve wanted for years!
I maintain a distribution of thousands of packages called yumda that I created specifically to deal with the problem of bundling native binaries and libraries for Lambda — I’m happy to now say that AWS has essentially made this project redundant 😄
Not Docker
To be clear, what’s been announced is not actually Lambda running Docker per se — it’s specifically using container images as the packaging mechanism. A little like zipping up your OS image, which then gets unzipped in Lambda’s environment when your function executes. But it’s very similar — the image is actually the main feature I (and many others) have wanted — because it allows you to bundle all your dependencies, including native binaries and libraries, using any (Linux) OS you want, into a portable package that can easily be tested locally and deployed remotely.
Loads of room
You also get a massive 10GB to do it all in, which overcomes another pain point many have had with trying to get large functions running on Lambda (eg those with ML models) — and is a huge step up from the previous 250MB limit.
Use standard tools
In this post I’ll show you how to use Container Image Support in Lambda with regular docker commands and versatile images like Alpine. We’ll see how you can test your images locally, and deploy them to Lambda.
The code for this tutorial can be found at https://github.com/mhart/pdf2png-demo. This post assumes you have docker installed on your machine.
Background
Let’s say we’re a web publisher and we want to create a service that can convert PDF files to PNGs whenever they’re uploaded, so we can use them as images in our web pages. In this case, we’ve found a PDF-to-PNG converter tool called pdftocairo which does just that, so we want to use it in our Lambda function.
Before Container Image Support, we would’ve needed to find a public Lambda Layer that already had this tool, or use yumda, or compile it ourselves for a Lambda environment with a particular directory structure. However, now that we can package our Lambda functions using container images, we can just install it using whichever Linux OS and package manager we like.
Bring your own OS
In this case I’ve chosen to use Alpine Linux to base the container image on. It’s a popular distribution for container images because it has a very small footprint and a strong track record with security.
I’ve also chosen to use Go as the language to develop the Lambda handler. Go has the advantage of compiling quickly and it can produce binaries that can talk to the Lambda Runtime API so can be used directly as the entrypoint in any container image without needing any extra software.
Getting our PDF conversion working
First we’ll create a container image we can run locally with docker to check that our tool works. We’ll create a program that will take a file at /tmp/input.pdf and turn it into a PNG file per page in /tmp/output, eg /tmp/output/converted-1.png, /tmp/output/converted-2.png, etc. We’ve chosen /tmp as it’s the only directory under which we can write files in Lambda (something to keep in mind if you’re used to a Docker environment where you can write to any OS path). Once we’ve confirmed this works, we can add the functionality we need to turn it into a Lambda handler and transfer the input/output files to/from S3.
Here’s the first version of our Go program, which we’ll save in src/main.go, that will execute a short shell script including the pdftocairo converter tool:
Then we create src/Dockerfile that contains the instructions to build our container image. It’s a multi-stage Dockerfile, with the first stage (labelled build-image) compiling our Go source files, and the final stage becoming the image we’ll test (and eventually deploy on Lambda).
We can use package managers
The package manager on Alpine Linux is called apk (similar to yum on Amazon Linux or apt on Ubuntu) — so we use apk addto install the tools we need, and then we copy over our program from the build image step.
We can then build the image (giving it the name pdf2png) by running docker build from the top-level of our project:
docker build -t pdf2png src
Then we’ll place a PDF file named input.pdf in our test directory and we can mount this directory as /tmp when we run the container:
docker run -v "$PWD/test":/tmp pdf2png
Now we should see a new directory, test/output that contains the converted PNG files. Our tool works! With regular old docker commands! Now we just need to wrap it in a Lambda handler.
Adding a Lambda handler
To turn this into an image that Lambda can execute, we can just modify our Go program to execute a handler function in the same way we would for the Go Lambda runtime.
We’ll keep the existing test functionality, but we’ll only run it if we pass in —-test as a command-line argument. Otherwise we’ll execute our Lambda handler.
The handler will respond to S3 object-created events — it will download the created S3 object locally, then run our pdf2png conversion function that we’ve already tested, then upload the PNG files to the same S3 bucket, under a different key prefix (see the demo repo for details of the download/upload functions)
The build instructions in our Dockerfile need to download the Go dependencies we need, and build our program for a Lambda environment, but the commands for the deployment image stay the same.
We build it in the same way we did before:
docker build -t pdf2png src
Thanks to Alpine, our image is actually pretty small, only 40MB! This has the advantage of being quick to build and deploy and upload/download.
And we can still test the conversion on a local file as we did before, now just passing in the --test flag:
docker run -v "$PWD/test":/tmp pdf2png --test
Testing our Lambda handler end-to-end
So far, we haven’t been able to check the rest of our function’s implementation though — the Lambda handler and the S3 upload/download.
Luckily, we can also test the full Lambda handler functionality with high fidelity, including our interaction with S3, using the Runtime Interface Emulator. This will run our program in an emulated Lambda environment and expose the same endpoint as the Lambda Invoke API so we can call it locally using an http client like curl or the AWS CLI.
There are a few ways we can get the aws-lambda-rie emulator binary onto our image for testing:
- Include it in the same image we deploy to Lambda
- Create a new image for testing
- Copy the emulator locally and mount it during
docker run
In this case we’ll go with option 2 and create a new image that extends the image we already created, but adds the emulator and sets it as the entrypoint. So test/Dockerfile looks like this:
And we can build it with:
docker build -t pdf2png-test test
When running live on Lambda, the function will get AWS credentials from the environment, in the form of AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY and AWS_SESSION_TOKEN variables, but we’re going to use a slightly more convenient method here. We’ll mount our ~/.aws directory into the container which will allow the SDK to use the same credentials as we would use with the AWS CLI. We can then use the AWS_REFION and AWS_PROFILE environment variables to choose our region and profile. As the emulator runs on port 8080 in the container, we’ll also need to expose that to our local machine, so we’ll map it to port 9000 locally.
We’ve now started the emulator running locally, and it’s listening for events. Let’s open up another terminal to send events to it.
We’ll need to create an event payload that matches the signature of our Lambda handler. There’s an example in the project repository that you can use. You can also generate one using the SAM CLI with the sam local generate command
As this test will actually download the S3 object we specify, and upload the converted files, we need to pass in a real S3 bucket and key with the event. So choose an existing S3 bucket you have, or create a new one (aws s3 mb) and upload a PDF file to test:
aws s3 cp test/input.pdf s3://my-bucket/upload/123/test-file.pdf
Then edit test/event.json to change the bucket to my-bucket and the key to upload/123/test-file.pdf.
Then you can invoke your function by calling the local endpoint with this event payload:
curl -d @test/event.json http://localhost:9000/2015-03-31/functions/function/invocations
Then you can see it execute it the terminal you ran the docker command in. The converted file should be uploaded to that same S3 bucket and you can use ctrl-c to exit the emulator.
Great! We’ve verified that our container image works with the Lambda runtime emulator and now we’re ready to deploy it.
Deploying
Container support requires your Lambda function code point to an image URI from an ECR Repository. The demo repo includes an infrastructure stack that will set this up for you, but here’s a guide if you want to do it manually:
Create an ECR repository, eg called pdf2png-app. The full name of this repository will be something like <accountid>.dkr.ecr.us-east-1.amazonaws.com/pdf2png-app
Then you can tag your image with this repository name
docker build -t <accountid>.dkr.ecr.us-east-1.amazonaws.com/pdf2png-app:v1 src
You’ll need to ensure docker is authenticated with ECR before you can push this image:
aws ecr get-login-password | docker login --username AWS --password-stdin <accountid>.dkr.ecr.us-east-1.amazonaws.com
And now you can push your tagged image to your repository:
docker push <accountid>.dkr.ecr.us-east-1.amazonaws.com/pdf2png-app:v1
Now that we have an image URI, we can use it as the source of our Lambda function. Here’s the full cloudformation template for our app that creates a container image Lambda triggered by an S3 bucket:
We can deploy this by passing in the image URI we just created:
Once this is deployed, you have an Image Function!
Using our live function
Congratulations! Now we can check that it works.
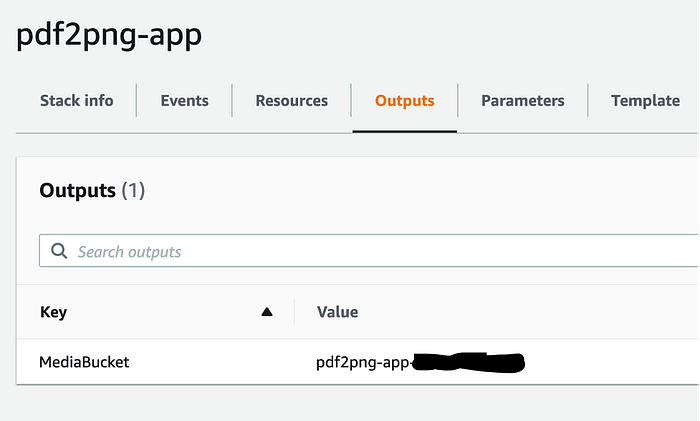
The S3 bucket created should be called: pdf2png-app-<accountid>. You can find the exact name in the Outputs tab of your pdf2png-app CloudFormation stack.
Then you can test the functionality by copying a PDF file to the S3 bucket in the appropriate prefix:
aws s3 cp test/input.pdf s3://pdf2png-app-<accountid>/upload/2020/12/01/123.pdf
And (a second or so later) observe the file has been converted into one or more PNG files!
aws s3 ls s3://pdf2png-app-<accountid>/converted/2020/12/01/123/
If there are downstream services that need to be notified when the conversion has completed, we could add notifications to our Lambda function using SNS or EventBridge too.
Conclusion
In this post I’ve shown you how container image support in Lambda makes it easy to create complex applications that rely on binary tools.
I’ve shown how you can use existing docker tooling to create and test your container images locally — including a full integration test talking to S3 — and deploy Lambda functions packaged using these images.
I’m looking forward to using container image support for other use cases too. With 10GB of image size, we can now deploy tools on Lambda that were previously difficult, if not impossible, such as machine learning and serverless continuous integration. It really opens up a new world of possibilities.
